The advent of computer technology in our time marked an informational upheaval in all spheres of human activity. But in order to ensure that all information does not become unnecessary garbage on the global Internet, a database system was invented in which materials are sorted, systematized, as a result of which they are easy to find and submit to subsequent processing. There are three main varieties - distinguish relational, hierarchical, and network databases.
Fundamental models
Returning to the emergence of databases, it is worth saying that this process was quite complicated, it originates along with the development of programmable equipment for information processing. Therefore, it is not surprising that the number of their models currently reaches more than 50, but the main ones are considered hierarchical, relational and network, which are still widely used in practice. What are they?
The hierarchical database has a tree structure and is composed of data of different levels, between which there are connections. The network database model is a more complex template. Its structure resembles a hierarchical, and the scheme is expanded and improved. The difference between the two is that the hereditary data of the hierarchical model can be associated with only one ancestor, and the network can have several of them. The structure of a relational database is much more complicated. Therefore, it should be disassembled in more detail.
The basic concept of a relational database
Such a model was developed in the 1970s by Dr. Edgar Codd. It is a logically structured table with fields describing the data, their relationships with each other, operations performed on them, and most importantly - the rules that guarantee their integrity. Why is the model called relational? It is based on the relationship (from lat. Relatio) between data. There are many definitions for this type of database. Relational tables with information are much easier to systematize and give processing than in a network or hierarchical model. How to do this? It is enough to know the features, model structure and properties of relational tables.
The process of modeling and compiling the basic elements
In order to create your own DBMS, you should use one of the modeling tools, think over what information you need to work with, design tables and relational single and multiple relationships between the data, fill in the entity cells and set the primary, foreign keys.
Table modeling and relational database design is done through free tools such as Workbench, PhpMyAdmin, Case Studio, dbForge Studio. After detailed design, you should save the graphically prepared relational model and translate it into the finished SQL code. At this stage, you can start work with sorting the data, their processing and systematization.
Features, structure, and terms associated with the relational model
Each source describes its elements in its own way, so for less confusion I would like to give a little hint:
- relational label = entity;
- layout = attributes = field name = column header of the entity;
- entity instance = tuple = record = label string;
- attribute value = entity cell = field.
To go to the properties of a relational database, you should know what basic components it consists of and what they are intended for.
- Essence. A relational database table can be one, or there can be a whole set of tables that characterize the described objects due to the data stored in them. They have a fixed number of fields and a variable number of records. The database relational model table is composed of rows, attributes, and layout.
- Record - a variable number of lines displaying data that characterize the described object. Numbering of records is done by the system automatically.
- Attributes are data that demonstrates a description of the columns of an entity.
- Field. Represents an entity column. Their number is a fixed value set during the creation or modification of the table.
Now, knowing the constituent elements of the table, we can proceed to the properties of the relational database model:
- The entities of a relational database are two-dimensional. Due to this property, it is easy to perform various logical and mathematical operations with them.
- The order of the attribute values and records in the relational table can be arbitrary.
- A column within one relational table must have its own individual name.
- All data in the entity column has a fixed length and the same type.
- Any record in essence is considered one data element.
- The constituent components of strings are one of a kind. A relational entity does not have identical rows.
Based on the properties of a relational DBMS, it is clear that the attribute values must be of the same type and length. Consider the features of attribute values.
The main characteristics of the fields of relational databases
Field names must be unique within the same entity. Relational database attribute or field types describe which category of data is stored in entity fields. The field of the relational database must have a fixed size, calculated in characters. Parameters and the format of attribute values determine how data is corrected in them. Still there is such a thing as a "mask", or "input template". It is intended to determine the configuration of data entry into the attribute value. Certainly, when writing the wrong data type in the field, an error notification should be issued. Also, some restrictions are imposed on field elements - conditions for checking the accuracy and accuracy of data entry. There is some mandatory attribute value that must be unambiguously filled with data. Some attribute strings may be filled with NULL values. Entering empty data into field attributes is allowed. Like the error notification, there are values that are automatically populated by the system - this is the default data. To speed up the search for any data, an indexed field is intended.
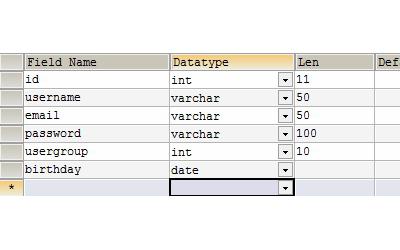
Diagram of a two-dimensional relational database table
Relational database schema| Attribute Name 1 | Attribute Name 2 | Attribute Name 3 | Attribute Name 4 | Attribute Name 5 |
| Element_1_1 | Element_1_2 | Element_1_3 | Element_1_4 | Element_1_5 |
| Element_2_1 | Element_2_2 | Element_2_3 | Element_2_4 | Element_2_5 |
| Element_3_1 | Element_3_2 | Element_3_3 | Element_3_4 | Element_3_5 |
For a detailed understanding of the model control system using SQL, it is best to consider a diagram using an example. We already know what a relational database is. A record in each table is one data item. To prevent data redundancy, normalization operations must be performed.
Basic rules for normalizing a relational entity
1. The value of the field name for the relational table must be unique, one of a kind (the first normal form is 1NF).
2. For a table that has already been reduced to 1NF, the name of any non-identifying column must be dependent on the unique identifier of the table (2NF).
3. For the entire table that is already in 2NF, each non-identifying field cannot depend on an element of another unidentified value (3NF entity).
Databases: relational relationships between tables
There are 2 main types of relational label relationships:
- "One to many." It occurs when one key record of table No. 1 matches several instances of the second entity. The key icon at one end of the drawn line indicates that the entity is on the “one” side, the second end of the line is often marked with an infinity symbol.
- The many-many relationship is formed in the event of the appearance of obvious logical interaction between several rows of one entity with a number of records in another table.
- If a one-to-one concatenation occurs between two entities, this means that the key identifier of one table is present in another entity, then one of the tables should be removed, it is superfluous. But sometimes, solely for security reasons, programmers deliberately separate the two entities. Therefore, hypothetically, a one-to-one relationship may exist.
Key Existence in a Relational Database
Primary and secondary keys identify potential database relationships. Relational relationships of a data model can have only one potential key, this will be the primary key. What is he like? The primary key is an entity column or a set of attributes, thanks to which you can access the data of a particular row. It must be unique, unique, and its fields cannot contain empty values. If the primary key consists of only one attribute, then it is called simple, otherwise it will be a component.
In addition to the primary key, there is also a foreign (foreign key). Many do not understand what is the difference between them. Let's analyze them in more detail using an example. So, there are 2 tables: “Dean's office” and “Students”. The entity "Dean" contains the fields: "Student ID", "Name" and "Group". The “Students” table has attribute values such as “Name”, “Group” and “Average mark”. Since the student ID may not be the same for several students, this field will be the primary key. “Name” and “Group” from the “Students” table can be the same for several people, they refer to the student ID number from the entity “Dean's office”, therefore they can be used as a foreign key.
Relational Database Model Example
For clarity, we give a simple example of a relational database model consisting of two entities. There is a table called "Dean".
The essence of "Dean's office" |
Student ID | Full name | Group |
111 | Ivanov Oleg Petrovich | IN-41 |
222 | Lazarev Ilya Alexandrovich | IN-72 |
333 | Konoplev Petr Vasilievich | IN-41 |
444 | Kushnereva Natalia Igorevna | IN-72 |
You need to make connections to get a complete relational database. The record "IN-41", like "IN-72", may be present more than once in the "Dean" plate, also the surname, name and patronymic of students in rare cases can coincide, therefore these fields cannot be made the primary key. We show the essence of "Students".
Students table |
Full name | Group | Average mark | Telephone |
Ivanov Oleg Petrovich | IN-41 | 3.0 | 2-27-36 |
Lazarev Ilya Alexandrovich | IN-72 | 3.8 | 2-36-82 |
Konoplev Petr Vasilievich | IN-41 | 3.9 | 2-54-78 |
Kushnereva Natalia Igorevna | IN-72 | 4.7 | 2-65-25 |
As we can see, the types of fields in relational databases are completely different. There are both digital and symbolic recordings. Therefore, the values of integer, char, vachar, date and others should be specified in the attribute settings. In the Dean table, the unique value is only the student ID. This field can be taken as a primary key. Name, group and phone from the entity "Students" can be taken as a foreign key that refers to the student ID. The connection is established. This is an example of a one-to-one model. Hypothetically, one of the tables is superfluous; they can be easily combined into one entity. So that the student ID numbers do not become universally known, the existence of two tables is quite possible.