The development of computer technology in the new information age raises many additional questions, opens up new opportunities and knowledge. But along with this, there are many dilemmas that need to be addressed. So, for example, when studying computer technology, it is important to understand how it processes, remembers and transfers files, what data encoding is and in what format information is measured. But the main subject of discussion is the question of what are the main approaches to measuring information. Examples and explanations of each aspect will be described in detail in this article.
Information in Computer Science
To begin to understand the information approaches of data storage, you first need to find out what information represents in the computer field and what it shows. After all, if we take computer science as a science, then its main object of study is precisely information. The very word of Latin origin and translated into our language means "familiarization", "explanation", "mixing." Each science uses different definitions of this concept. In the computer sphere, this is all the information about various phenomena and objects surrounding us that reduce the degree of uncertainty and the degree of our ignorance about them. But in order to store all files, data, symbolic characters in an electronic computer, you need to know the algorithm for converting them to binary form and the existing units for measuring the amount of data. An alphabetic approach to measuring information shows exactly how a computer machine converts characters into binary code of zeros and ones.
Information coding by electronic computer
Computer technology is capable of recognizing, processing, storing and transmitting only information data in binary code. But if it is an audio recording, text, video, graphic image, how is a machine capable of converting different types of data into a binary type? And how are they in this form stored in memory? Answers to these questions can be found if you know the alphabetical approach to determining the amount of information, the substantive aspect and the technical essence of coding.
Encoding information is to encrypt characters in a binary code consisting of the characters "0" and "1". It is technically easy to organize. There is a signal, if it is one, zero indicates the opposite. Some people wonder why a computer cannot, like the human brain, store complex numbers, because they are smaller in size. But electronic computing is easier to operate with huge binary code than storing complex numbers in your memory.
Calculus systems in the computer field
We are used to counting from 1 to 10, add, subtract, multiply and do various operations on numbers. The computer is capable of operating with only two numbers. But does it in fractions of a millisecond. How does a computer machine encode and decode characters? This is a fairly simple algorithm, which can be considered by example. We will consider the alphabetic approach to measuring information, units of data a little later, after the essence of coding and decoding of data becomes clear.
There are many computer programs that visually translate calculus systems or text strings into binary code and vice versa.
We will carry out the calculations manually. Encoding information is done by dividing it by 2. So, let's say we have the decimal number 217. We need to convert it to binary code. To do this, divide it by the number 2 until the moment when the remainder is zero or one.
- 217/2 = 108 with the remainder 1. Separately we write out the remainders, it is they who will create our final answer.
- 108/2 = 54. Here the remainder is the number 0, since 108 is completely divisible. Do not forget to mark yourself the leftovers. After all, if you lose at least one digit, the original number will already be different.
- 54/2 = 27, remainder 0.
- 27/2 = 13, write 1 in the remainder. Our numbers from the remainder create a binary code that must be read in the reverse order.
- 13/2 = 6. Here the unit is in the remainder, we write it out.
- 6/2 = 3 with a remainder of 0. In the final answer, the numbers should be one more than all the actions that you performed.
- 3/2 = 1 with remainder 1. We write the remainder and the number 1, which is the final division.
If you fill out the answer, starting with the number in the first action, the result is 10011011, but this is not true. The binary number must be rewritten in reverse order. Here is the final result of the translation of the number: 11011001. A substantial and alphabetical approach to measuring information uses data of this format for storage and transmission. The binary code is written to the code table and stored there until you need to display it on the monitor screen. Then the information is translated into the form familiar to us, called decoding.
The picture clearly shows the algorithm for converting from binary to decimal code. It is carried out according to a simple formula. We multiply the first digit of the code by 2 to the power of 0, add the next digit multiplied by 2 to the greater extent, and so on. As a result, as can be seen from the picture, we get the same number as the original when encoding.
Alphabetical approach to measuring information: essence, units
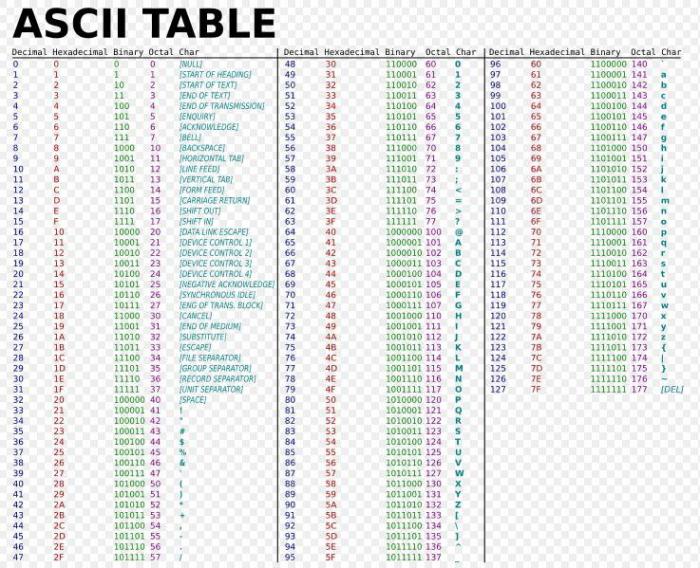
To measure the amount of data in a text sequence of characters, you must use the existing approach. The content of the text is not important here, the main thing is the quantitative ratio of the characters. Thanks to this aspect, the value of the text message encoded on the computer is calculated. In accordance with this approach, the quantitative value of the text is proportional to the number of characters entered from the keyboard. Due to this, the method of measuring information volume is often called volumetric. Symbols can be completely different in size. It is clear that such numbers as 0 and 1 carry 1 bit of information, and letters, punctuation, space - a different weight. You can look at the ASCII table to find out the binary code of one or another character. To calculate the text volume we need, we need to add the weight of all the characters - the components of the whole text. This is the alphabetical approach to determining the amount of information.
In computer science, there are many terms that are increasingly used in everyday life. So, the alphabet in computer science means a set of all characters, including brackets, space, punctuation marks, Cyrillic characters, Latin letters, which are nothing more than a text component. Here there are two definitions by which this value will be calculated.
1. Thanks to the first definition, it is possible to calculate the occurrence of characters in a text message when their probability of occurrence is completely different. So, we can say that some letters in Russian words appear very rarely, for example, “” or “”.
2. But in some cases it is more expedient to calculate the value we need, presenting the equiprobable appearance of each symbol. And here a different calculation formula will be used.
This is the alphabetic approach to measuring information.
Equiprobable occurrence of characters in a text file
To explain this definition, it must be assumed that all characters in the text or message appear with the same frequency. To calculate how much memory they occupy in a computer, you need to plunge into the theory of probability and simple logical conclusions.
Let's say the text is displayed on the monitor screen. We are faced with the task of calculating how much computer memory it occupies. Let the text consist of 100 characters. It turns out that the probability of the appearance of one letter, symbol or sign will be one hundredth of the total volume. If you read a book on probability theory, you can find such a fairly simple formula that will accurately determine the numerical value of the chance of a particular character appearing at any position in the text.
Probably, not everyone will be interested in proving formulas and theorems, therefore, given the formulas of famous scientists, the calculated expression is derived:
i = log 2 (1 / p) = log 2 N (bit); 2 i = N,
where i is the quantity that we need to know, p is the numerical value of the possibility of the occurrence of the character in the text position, N in most cases is 2, because the computer machine encodes the data into a binary code consisting of two quantities.
The alphabetic volumetric approach to measuring information assumes that the weight of one symbolic character is 1 bit - the minimum unit of measurement. By the formula, you can determine what is equal to bytes, kilobytes, megabytes, etc.
Different chance of occurrence of characters in the text
If we assume that the characters appear with different frequencies (respectively, and in any position of the text their probability of occurrence is different), then we can say that their information weight is also different. It is necessary to calculate the measurement of information using a different formula. The alphabetic approach is universal in that it implies both equal and different possibilities of the frequency of occurrence of a sign in the text. We will not touch on the complex formula for calculating this value, taking into account the different probability of occurrence of the symbol. It must be understood that such letters as "b", "x", "f", "h" are much less common in Russian words. Therefore, it becomes necessary to consider the frequency of occurrence using a different formula. After some calculations, scientists came to the conclusion that the informational weight of rare characters is much larger than the weight of letters that are often found. To calculate the volume of the text, it is necessary to take into account the repetition size of each character and its information weight, as well as the size of the alphabet.
Measurement of information: subtleties of the substantive aspect
You can ignore the alphabetical approach to measuring information. Computer science offers another aspect of data measurement - meaningful. Here a slightly different problem is already being solved. Suppose a person sitting at a computer receives information about a phenomenon or some object. It is clear in advance that he does not know anything, so there is a certain number of possible or expected options. After reading the message, the uncertainty disappears, there remains one option, the value of which must be calculated. We turn to the auxiliary formula. The value will be calculated in the minimum unit - bits. Like the alphabetical approach to measuring the amount of information, the correct formula will be chosen taking into account 2 possible situations: different and equal probability of occurrence of events.
Events met with equal probability
As in the case when an objective alphabetical approach is applied to measuring information, the desired formula with a meaningful approach is calculated taking into account the already known regularity, which was derived by the scientist Hartley:
2 i = N,
where i is the magnitude of the event that we need to find, and N is the number of events encountered with equiprobable frequency. The value i is considered in the minimum unit of calculation - bits. Can i be expressed in terms of the logarithm.
Example of calculating an equiprobable event
Suppose we have 64 dumplings on a plate, one of which has a surprise instead of meat. It is necessary to calculate how much information the event contains when it was this dumpling that was pulled out with a surprise, that is, to measure the information. The alphabetical approach is as simple as the objective. In two cases, the same formula would be used to calculate the quantitative volume of information materials. We substitute the well-known formula of the quantity: 2 i = 64 = 2 6 . Result: i = 6 bits.
Information measurement taking into account different probability of occurrence of an event
Suppose we have some event with probability of occurrence p. We assume that the quantity i calculated in bits is a number characterizing the fact that an event has occurred. Based on this, it can be argued that the values can be calculated according to the existing formula: 2 i = 1 / p.
Differences between the alphabetic and informative approaches to the information dimension
How does the volumetric approach differ from the content one? After all, the formulas for calculating the amount of information are exactly the same. The difference is that the alphabetic aspect can be used if you work with texts, and the substantial one allows you to solve any problems of probability theory, calculate the amount of information of an event taking into account its likely occurrence.
conclusions
The alphabetic approach to measuring information, as well as the informative one, makes it possible to find out what units of data and how much text characters or any other information will occupy. We can translate any text and numerical files, messages into computer code and vice versa, while always know how much memory they will occupy in a computer computer.