Information coding is an incredibly wide area of knowledge. Of course, it is directly related to the development of digital technology. In many modern educational institutions, the most popular topic is information coding. Today we will study the basic interpretations of this phenomenon in relation to various aspects of computer operation. We will try to answer the question: "Is coding a process, a method, a tool, or all these phenomena at the same time?"
Zeros and ones
Almost any type of data that is displayed on a computer screen, one way or another, is a binary code consisting of zeros and ones. This is the simplest, "low level" way to encrypt information, allowing the PC to process data. The binary code is universal: it is understood by all computers without exception (in fact, for this it was created to standardize the use of information in digital form).
The basic unit that binary encoding uses is a bit (from the phrase "binary digit" - "double digit"). It is either 0 or 1. As a rule, bits are not used individually, but are combined in 8-digit sequences - bytes. Each of them, thus, can contain up to 256 combinations of zeros and ones (2 to the 8th power). To record significant amounts of information, as a rule, not single bytes are used, but larger-scale quantities - with the prefixes "kilo", "mega", "giga", "tera", etc., each of which is 1000 times larger than the previous one .
Text encoding
The most common form of digital data is text. How is it encoded? This is a fairly easy to explain process. A letter, punctuation mark, digit or symbol can be encoded using one or more bytes, that is, the computer sees them as a unique sequence of zeros and ones, and then, in accordance with the embedded recognition algorithm, displays on the screen. There are two main world standards for the "encryption" of computer text - ASCII and UNICODE.
In ASCII, each character is encoded with only one byte. That is, through this standard, you can "encrypt" up to 256 characters - which is more than enough to display the characters of most alphabets of the world. Of course, all existing national letter systems that exist today will not fit into this resource. Therefore, each alphabet has its own "subsystem" of encryption. Information is being encoded using sign systems adapted to national writing patterns. However, each of these systems, in turn, is an integral part of the global ASCII standard, adopted internationally.
Within the ASCII system, this same resource of 256 characters is divided into two parts. The first 128 are characters reserved for the English alphabet (letters a to z), as well as numbers, basic punctuation, and some other characters. The second 128 bytes are reserved, in turn, for national letter systems. This is the "subsystem" for non-English alphabets - Russian, Hindi, Arabic, Japanese, Chinese and many others.
Each of them is presented in the form of a separate encoding table. That is, it can happen (and, as a rule, this happens) so that the same sequence of bits will be responsible for different letters and symbols in two separate "national" tables. Moreover, in connection with the peculiarities of the development of the IT sphere in different countries, even they differ. For example, for the Russian language, two coding systems are most common: Windows-1251 and KOI-8. The first appeared later (as well as the operating system itself, consonant with it), but now it is used by many IT specialists as a matter of priority. Therefore, the computer, so that it can be guaranteed to read Russian text on it, must be able to correctly recognize both tables. But, as a rule, there are no problems with this (if the PC has a modern operating system).
Text encoding techniques are constantly being improved. In addition to the "single-byte" ASCII system, capable of handling only 256 values for characters, there is also a "double-byte" UNICODE system. It is easy to calculate that it allows text encoding in an amount equal to 2 to the 16th power, that is 65 thousand 536. It, in turn, has resources for simultaneously coding practically all existing national alphabets of the world. Using UNICODE is no less common than using the "classic" ASCII standard.
Graphics coding
Above, we determined how the texts are “encrypted” and how bytes are used. What about digital photos and pictures? Also pretty simple. Similar to how this happens with the text, the same bytes play the main role in the encoding of computer graphics.
The process of constructing digital images is generally similar to the mechanisms on which the television works. On the TV screen, if you look closely, the picture consists of many separate points, which together form shapes recognizable at some distance by the eye. The television matrix (or CRT projector) receives the horizontal and vertical coordinates of each of the points from the transmitter and gradually builds the image. The computer-aided principle of graphics encoding works the same way. The "encryption" of images bytes is based on the specification of each of the screen points of the corresponding coordinates (as well as the color of each of them). That is, in simple terms. Of course, graphic coding is a much more complicated process than the same text.
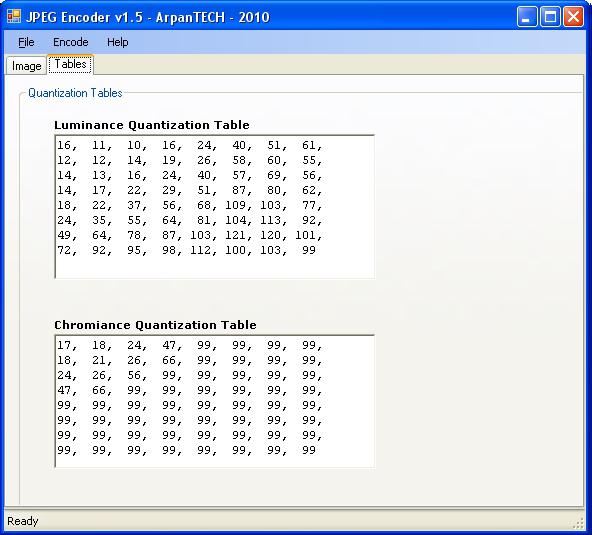
The method of assigning points the corresponding coordinates and color parameters is called "raster". Similarly, many computer graphics file formats are referred to. The coordinates of each of the image points, as well as their color, are recorded in one or more bytes. What determines their number? Mainly on how many shades of color to be "encrypted". One byte, as you know, is 256 values. If so many shades are enough for us to build a picture, we will get by with this resource. In particular, we may have 256 shades of gray. And this will be enough to encode almost any black and white image. In turn, for color images this resource will not be enough: the human eye, as you know, is able to distinguish up to several tens of millions of colors. Therefore, a “reserve" is needed not in 256 values, but in hundreds of thousands of times more. Why not a single byte is used to encode points, but several: according to the standards existing today there can be 16 (you can "encrypt" 65 thousand 536 colors) or 24 (16 million 777 thousand 216 colors).
Unlike textual standards, the diversity of which is comparable to the number of world languages, the graphics are somewhat simpler. The most common file formats (such as JPEG, PNG, BMP, GIF, etc.) are recognized equally well on most computers.
There is nothing difficult to understand by what principles the coding of graphic information is carried out. The 9th grade of any high school in Russia, as a rule, includes a computer science course, where similar technologies are disclosed in sufficient detail in a very simple and clear language. There are also specialized training programs for adults - they are organized by universities, lyceums, or also schools.
Therefore, modern Russian people have room to learn about codes that are of practical importance in terms of computer graphics. And if you want to get acquainted with the basic knowledge yourself, you can get available training materials. These include, for example, the chapter "Coding of Graphic Information (Grade 9, the textbook" Computer Science and ICT "authored by N. D. Ugrinovich).
Audio Encoding
The computer is regularly used to listen to music and other audio files. As with text and graphics, any sound on a PC is all the same bytes. They, in turn, are “decrypted” by an audio card and other microcircuits and converted into audible sound. The principle here is about the same as with the phonograph records. In them, as you know, each sound corresponds to a microscopic groove on plastic, which is recognized by the reader, and then voiced. Everything looks similar on a computer. Only bytes play the role of grooves, in the nature of which, as in the case with text and pictures, binary encoding lies.
If in the case of computer images a single element is a dot, then when recording sound, this is the so-called "countdown". In it, as a rule, two bytes are registered, generating up to 65 thousand 536 sound micro-vibrations. However, in contrast to how this happens when constructing images, to improve the sound quality, not by adding extra bytes (they are obviously more than enough), but by increasing the number of “samples”. Although some byte audio systems use both a smaller and a larger number. When sound coding is carried out, one second acts as a standard unit of measurement of "flux density" of bytes. That is, the micro-oscillations encrypted using 8 thousand samples per second will obviously be of lower quality than the sequence of sounds encoded by 44 thousand “samples”.
The international standardization of audio files, as well as in the case of graphics, is well developed. There are several typical formats of sound media - MP3, WAV, WMA, which are used all over the world.
Video encoding
A kind of "hybrid scheme" in which sound encryption is combined with picture encoding is used in computer videos. Typically, films and clips consist of two types of data - this is the sound itself and the accompanying video sequence. How the first component is “encrypted”, we described above. The second is a bit more complicated. The principles here are different than the graphic encoding discussed above. But due to the universality of the "concept" of bytes, the essence of the mechanisms is quite understandable and logical.
Recall how the film is arranged. It is nothing more than a sequence of individual frames (there are usually 24 of them). Computer videos are arranged in exactly the same way. Each frame is a picture. About how it is built using bytes, we defined above. In turn, there is a certain area of code in the video sequence that allows you to associate individual frames with each other. A kind of digital film substitute. A separate unit of measurement of the video stream (similar to points for pictures and samples for sound, as in the "film" format of films and clips), is considered to be a frame. The last in one second, in accordance with accepted standards, may be 25 or 50.
As in the case of audio, there are common international standards for video files - MP4, 3GP, AVI. Filmmakers and movie makers are trying to produce media samples that are compatible with as many computers as possible. These file formats are among the most popular, they open on almost any modern PC.
Data compression
Storage of computer data is carried out on various media - disks, flash drives, etc. As we have said above, bytes, as a rule, are "surrounded" by the prefixes "mega", "gigabyte", "tera", etc. In some cases the size of the encoded files is such that it is impossible to place them with the available resources on the disk. Then various types of data compression methods are used. They, in fact, also represent coding. This is another possible interpretation of the term.
There are two main mechanisms for data compression. According to the first of them, the sequence of bits is recorded in "packed" form. That is, the computer cannot read the contents of the files (play it as text, picture or video) if it does not carry out the “unpacking” procedure. A program that performs data compression in this way is called an archiver. The principle of its work is quite simple. Data archiving as one of the most popular methods with which you can encode information, school-level computer science is studying without fail.
As we recall, the process of "encrypting" files in bytes is standardized. Take the ASCII standard. To, say, encrypt the word "hello", we need 6 bytes, based on the number of letters. That is how much space a file with this text will occupy on disk. What happens if we write the word hello 100 times in a row? Nothing special - for this we need 600 bytes, respectively, the same amount of disk space. However, we can use an archiver to create a file in which, using a much smaller number of bytes, a command that looks something like this: “hello times 100” will be “encrypted”. After counting the number of letters in this message, we conclude that to write such a file we need only 19 bytes. And the same amount of disk space. When “unpacking” the archive file, “decryption” occurs, and the text takes on its original form with “100 greetings”. Thus, using a special program that uses a special encoding mechanism, we can save a significant amount of disk space.
The process described above is quite universal: no matter what sign systems are used, coding information for compression is always possible through data archiving.
What is the second mechanism? To some extent, it is similar to that used in archivers. But its fundamental difference is that a compressed file can be displayed by a computer without the procedure of "unpacking". How does this mechanism work?
As we recall, in its original form, the word "hello" takes 6 bytes. However, we can go to the trick and write it like this: "prvt." 4 bytes come out. All that remains to be done is to "teach" the computer to add the letters that we removed in the process of displaying the file. It must be said that in practice the “training” process is not necessary to organize. The basic mechanisms for recognizing missing characters are embedded in most modern PC programs. That is, the bulk of the files that we deal with every day, one way or another, is already "encrypted" by this algorithm.
Of course, there are "hybrid" information coding systems that allow for data compression while simultaneously involving both of the above approaches. And they are likely to be even more effective in terms of saving disk space than each individually.
Of course, using the word "hello", we have outlined only the basic principles of the operation of data compression mechanisms. In reality, they are much more complicated. Various information coding systems can offer incredibly complex file compression mechanisms. However, we can see how to save disk space, practically without resorting to deterioration in the quality of information on a PC. Especially significant is the role of data compression when using pictures, audio and video - these types of data are more demanding of disk resources than others.
What other "codes" are there?
As we said at the very beginning, coding is a complex phenomenon. Having dealt with the basic principles of encoding digital data based on bytes, we can touch on another area. It is associated with the use of computer codes in slightly different meanings. Here, by “code” we mean not a sequence of zeros and ones, but a combination of different letters and symbols (which, as we already know, are already made of 0 and 1), which has practical significance for the life of a modern person.
Program code
At the heart of the work of any computer program is code. It is written in a language understood by a computer. PC, decrypting the code, performs certain commands. A distinctive feature of a computer program from another type of digital data is that the code contained in it is able to "decrypt" itself (the user only needs to start this process).
Another feature of the programs is the relative flexibility of the code used. That is, a person can give the same tasks to a computer using a sufficiently large set of “phrases”, and, if necessary, in another language.
Document Markup Code
Another practically significant area of application of the letter code is the creation and formatting of documents. As a rule, simply displaying the characters on the screen is not enough from the point of view of the practical significance of using a PC. In most cases, the text should be built using a font of a certain color and size, accompanied by additional elements (such as, for example, tables).All these parameters are set, as in the case of programs, in special languages that are understandable to the computer. Having recognized the “commands”, the PC displays the documents exactly as the user wishes. In addition, texts can be equally formatted, similar to how it happens with programs, using different sets of "phrases" and even in different languages.
. , . .
Data encryption
Another interpretation of the term “code” as it relates to computers is data encryption. Above, we used this word as a synonym for the term "coding", and this is permissible. In this case, by encryption we mean a different kind of phenomenon. Namely, the encoding of digital data in order to prohibit access to it by other people. Protecting computer files is the most important area of activity in the IT field. This is actually a separate scientific discipline, it also includes school computer science. Encoding files to prevent unauthorized access is a task whose importance is set forth for citizens of modern countries as early as childhood.
What are the mechanisms by which data is encrypted? In principle, it is as simple and understandable as all the previous ones that we examined. Coding is a process that can be easily explained in terms of the basic principles of logic.
Suppose we need to convey the message "Ivanov goes to Petrov" so that no one can read it. We trust to encrypt the message to the computer and see the result: "10-3-1-15-16-3-10-5-7-20-11-17-6-20-18-3-21". This code, of course, is very simple: each digit corresponds to the serial number of the letters of our phrase in the alphabet. “I” stands at 10th place, “B” - at 3, “A” - at 1, etc. But modern computer coding systems can encrypt data so that it will be incredibly difficult to select a key to them.